Implementation-First AI for Real Business Workflows
Why the AI conversation keeps missing the point
Most businesses don't fail with AI because "the model isn't smart enough." They fail because the implementation is missing: clear scope, quality control, risk boundaries, and a clean knowledge layer. That gap is showing up everywhere, including in workforce data: ManpowerGroup reports that employers are struggling most with AI skills and that difficulty filling roles remains widespread.
At the same time, large enterprise programs are strongly signaling what "AI adoption" actually means in practice: moving from pilots to production requires repeatable delivery playbooks, governance, and teams who can embed AI into real environments. For example, Accenture and Anthropic publicly describe structured efforts to help enterprises go from pilots to full-scale deployment, including large-scale training and partner enablement.
The capabilities that make AI safe and useful in production
Across many implementations, the same capability blocks recur. Below is a plain-language translation of the "seven skills" idea - reframed away from jobs and toward what businesses must build and operate.
1. Clarity of intent (specification precision)
AI systems (especially agents) don't reliably "read between the lines," so you need crisp definitions: what the workflow does, what it must never do, when to escalate, what to log, and what "done" means.
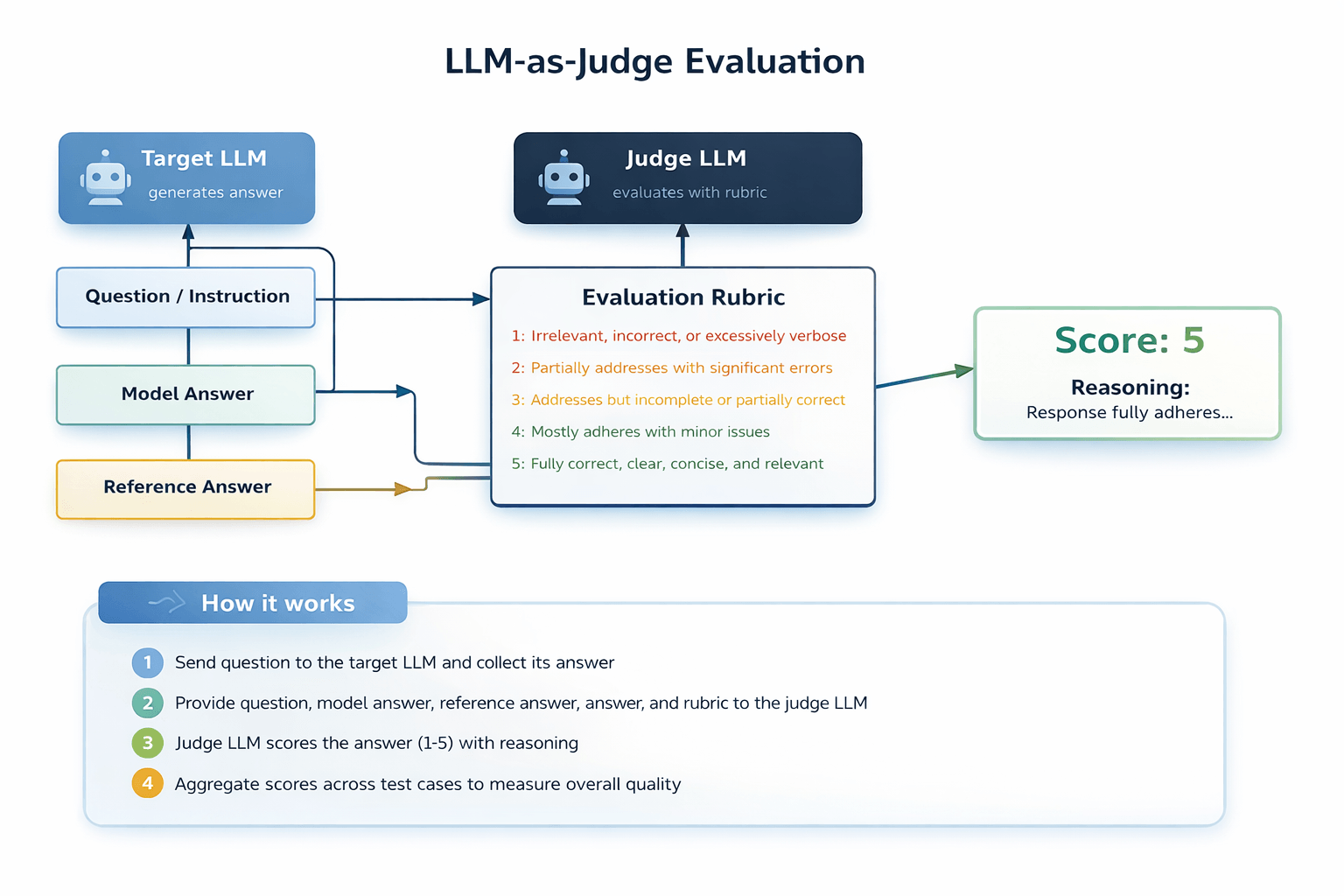
2. Quality judgment (evaluation)
If you can't test it, you can't trust it. This means turning real business checks (how you review work today) into repeatable tests and using unambiguous pass/fail criteria that different experts would agree on.
3. Decomposition and delegation (single agent vs multi-agent)
You get reliability by breaking work into smaller steps with clear handoffs and guardrails - similar to project management, but more rigid because agents are less forgiving about ambiguity.
4. Failure pattern recognition
Production failures are often not dramatic. They can be subtle: drift from the original spec, the wrong tool being used, the wrong context being retrieved, or "plausible output" that's functionally wrong. You need a discipline for diagnosing these patterns and designing checks to catch them.
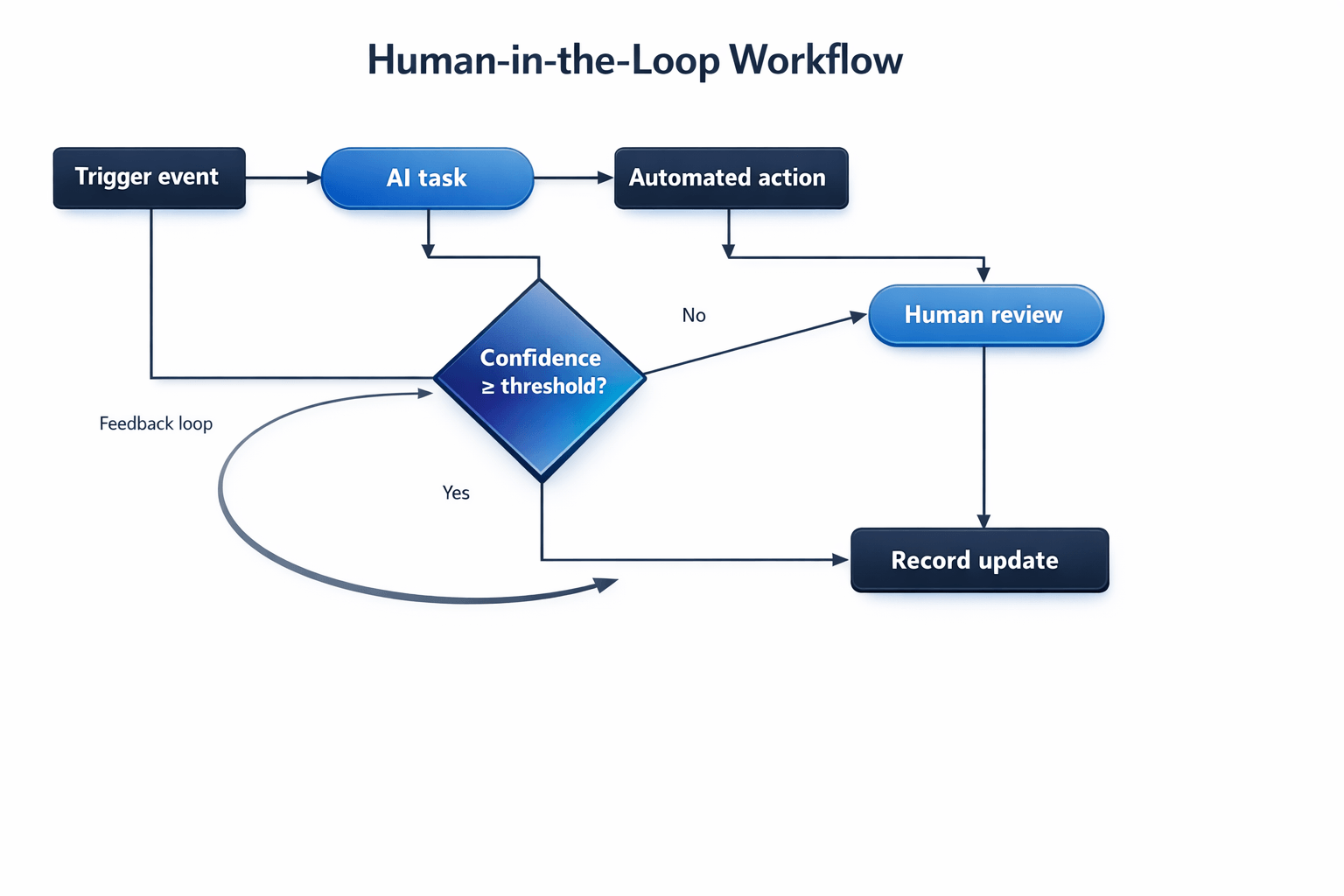
5. Trust and security design
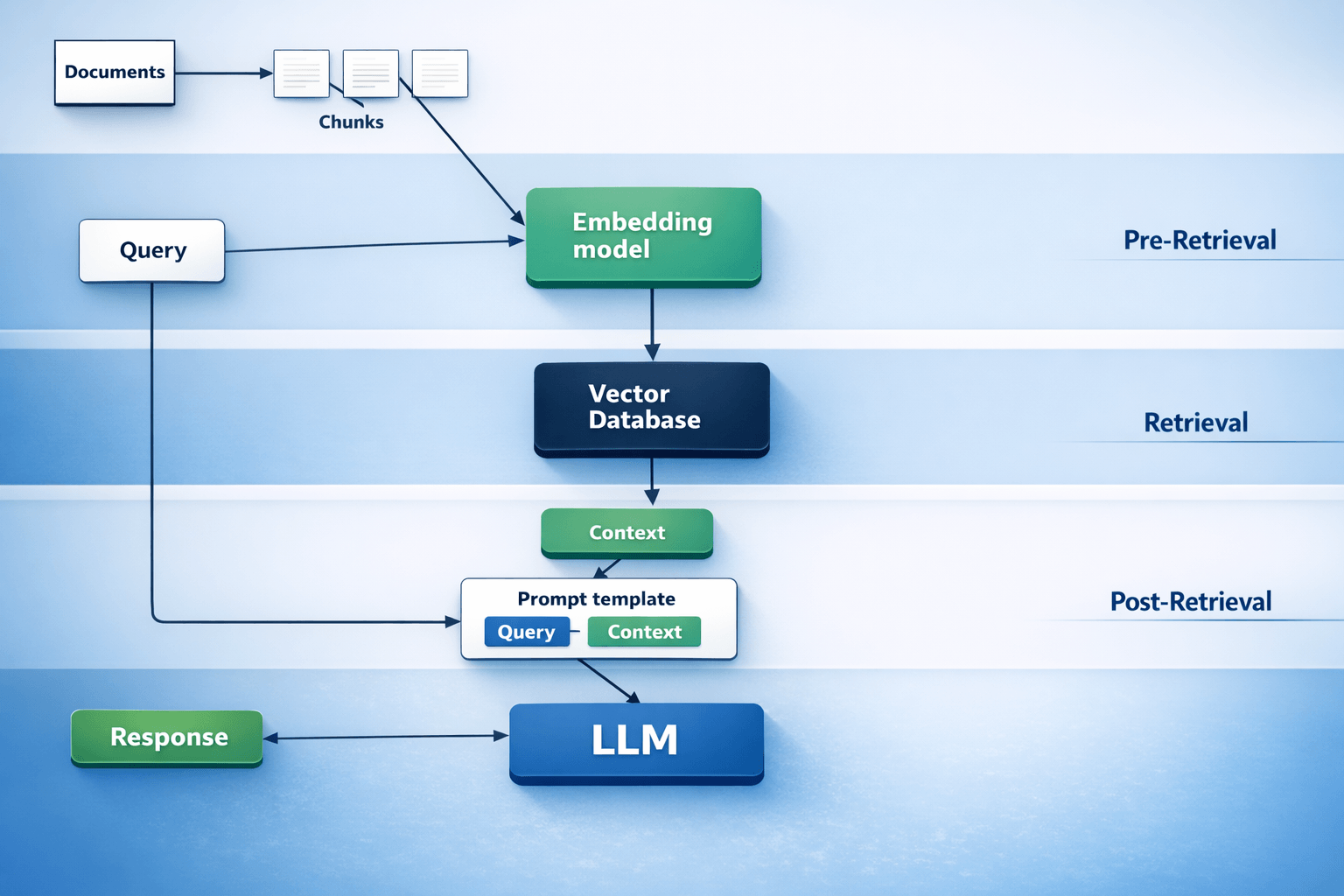
6. Context architecture (your "AI-ready" knowledge layer)
If the AI can't consistently find the right internal facts, it will confidently produce the wrong answer. Building context is more than dumping PDFs into a folder: it's organizing, cleaning, controlling retrieval, and continuously debugging "why did it pick that document?"
7. Cost and ROI discipline (token economics)
Even when outputs look good, you still need a business case: which steps truly need a premium model, which steps can be cheaper, and what the measurable return is.
The customer-side team you actually need
In smaller businesses, the biggest misconception is: "We need one AI person." In practice, you need coverage across a few responsibilities - sometimes spread across a couple of people, sometimes provided by a partner.
A practical "AI implementation squad" for real estate and legal operations usually needs:
- Process owner (business lead). Knows the workflow, defines success metrics, decides what can be automated vs must remain human.
- Domain expert. Owns policy and correctness (leases, contracts, compliance rules, client communications).
- Context / data owner. Makes sure the AI pulls from clean, approved sources (policies, precedents, templates) and that retrieval can be audited.
- Automation + integration builder. Connects your documents, CRM/case management, email, intake forms, reporting, and permissioning so AI can act inside real systems.
- Quality + risk owner. Turns "sounds right" into "is right," maintains evals, monitors failures, and adds guardrails against known attack patterns like prompt injection and unsafe output handling.
You don't need a large internal department to cover these responsibilities - but you do need them covered. That's why implementation partners outperform "tool-only" rollouts: they bring the full set, already coordinated.
A simple workflow for deploying AI without breaking your business
A reliable implementation approach looks closer to operations engineering than experimentation:
Start with what you already check manually, then convert real failures (tickets, QA notes, edge cases) into tests before expanding scope. This is exactly the approach recommended in hands-on guidance for agent evals: begin with existing manual checks, use real bug/support queues, and write unambiguous tasks with reference solutions.
Build guardrails outside the model: permissions, output validation, logging, and escalation rules. This matches security guidance that warns against relying only on prompts for strict behavior control and highlights common LLM risks (prompt injection, insecure output handling, excessive agency).
Treat the knowledge layer as a product: control what can be retrieved, reduce "context noise," and design tools and tool outputs so agents don't waste context or get steered into failure.
Use both automated scoring and human review to discover edge cases and "looks fine but wrong" outcomes. This hybrid pattern also shows up in practical agent-evaluation work: automated judging scales evaluation, while humans still catch what automation misses (like subtle source-quality failures).
Your Project, Our Expertise.
Tell us what you’re working on, and we’ll craft a solution that makes your business run better.
